Coffee with Steve - dbt
Hi, I’m Steve with GrowthLoop. Over the last 2 years, I’ve used dbt daily to build data models on Redshift, Snowflake, and BigQuery.
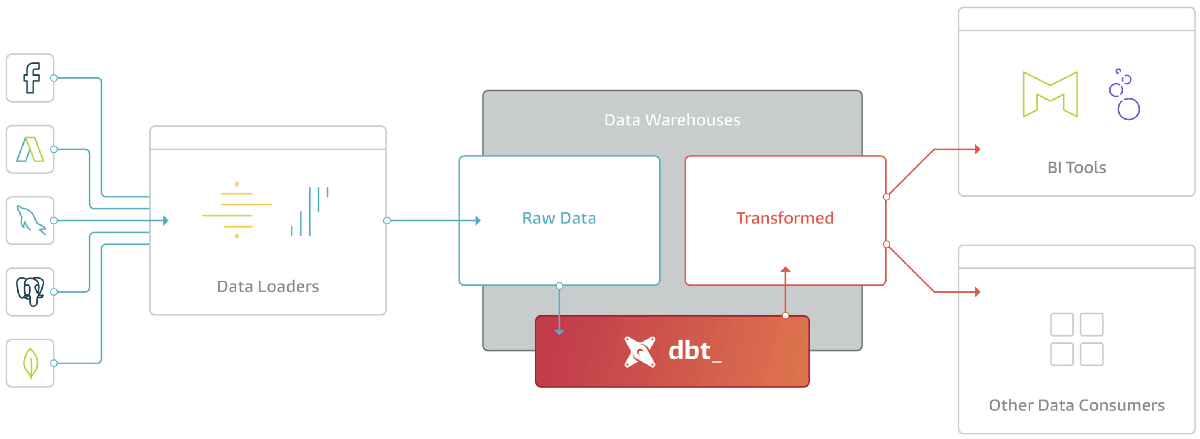
This is the start of a series of articles on tips, best practices, and general knowledge about dbt and how to use it to build complex data models in your Cloud Data Warehouse. This series will focus on use in BigQuery but is generally applicable to your data warehouse of choice.